On 6th of September, Cachix experienced 3 hours of downtime.
We’d like to let you know exactly what happened and what measures we have taken to prevent such an event from happening in the future.
Timeline (UTC)
- 2019-09-06 17:15:05: cachix.org down alert triggered
- 2019-09-06 20:06:00: Domen gets out of MuniHac dinner in the basement and receives the alert
- 2019-09-06 20:19:00: Domen restarts server process
- 2019-09-06 20:19:38: cachix.org is back up
Observations
The backend logs were full of:
Sep 06 17:02:34 cachix-production.cachix cachix-server[6488]: Network.Socket.recvBuf: resource vanished (Connection reset by peer)
And:
(ConnectionFailure Network.BSD.getProtocolByName: does not exist (no such protocol name: tcp)))
Most importantly, there were no logs after downtime was triggered and until the restart:
Sep 06 17:15:48 cachix-production.cachix cachix-server[6488]: Network.Socket.recvBuf: resource vanished (Connection reset by peer)
Sep 06 20:19:26 cachix-production.cachix systemd[1]: Stopping cachix server service...
Our monitoring revealed an increased number of nginx connections and file handles (the time are in CEST - UTC+2):
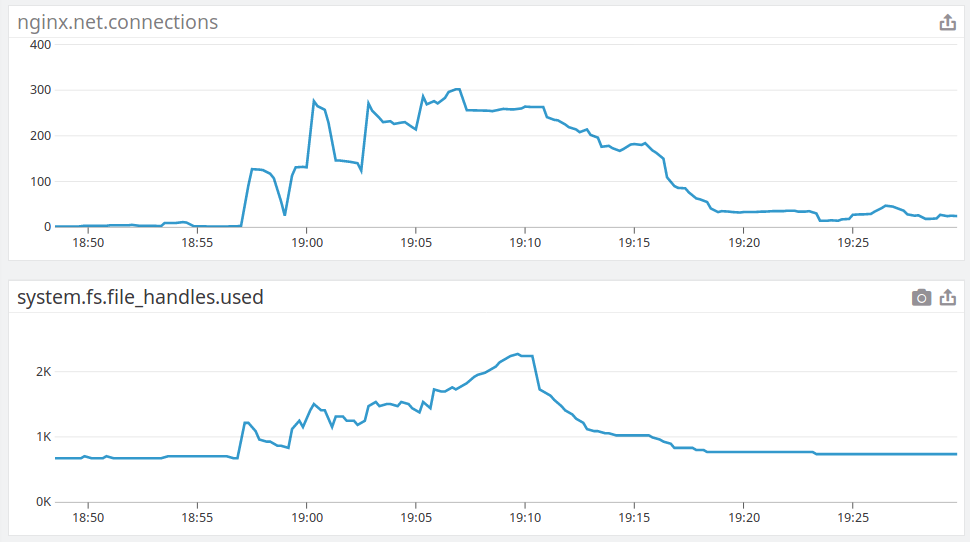
Conclusions
-
The main cause for downtime was hanged backend. The underlying cause was not identified due to lack of information.
-
The backend was failing some requests due to reaching the limit of 1024 file descriptors.
-
The duration of the downtime was due to the absence of a telephone signal.
What we’ve already done
-
To avoid any hangs in the future, we have configured systemd watchdog which automatically restarts the service if the backend doesn’t respond for 3 seconds. Doing so we released warp-systemd Haskell library to integrate Warp (Haskell web server) with systemd, such as socket activation and watchdog features.
-
We’ve increased file descriptors limit to 8192.
-
We’ve set up Cachix status page so that you can check the state of the service.
-
For a better visibility into errors like file handles, we’ve configured sentry.io error reporting. Doing so we released katip-raven for seamless Sentry integration of structured logging which we also use to log Warp (Haskell web server) exceptions.
-
Robert is now fully onboarded to be able to resolve any Cachix issues
-
We’ve made a number of improvements for the performance of Cachix. Just tuning GHC RTS settings shows 15% speed up in common usage.
Future work
-
Enable debugging builds for production. This would allow systemd watchdog to send signal SIGQUIT and get an execution stack in which program hanged.
We opened nixpkgs pull request to lay the ground work to be able to compile debugging builds.
However there’s a GHC bug opened showing debugging builds alter the performance of programs, so we need to asses our impact first.
-
Upgrade network library to 3.0 fixing unneeded file handle usage and a possible candidate for a deadlock.
Stackage just included network-3.* in latest snapshot so it’s a matter of weeks.
-
Improve load testing tooling to be able to reason about performance implications.
Summary
We’re confident such issues shouldn’t affect the production anymore and since availability of Cachix is our utmost priority, we are going to make sure to complete the rest of the work in a timely manner.
What we do
Automated hosted infrastructure for Nix, reliable and reproducible developer tooling, to speed up adoption and lower integration cost. We offer Continuous Integration and Binary Caches.